In our second post we described attacks on models and the concepts of input privacy and output privacy. ln our previous post, we described horizontal and vertical partitioning of data in privacy-preserving federated learning (PPFL) systems. In this post, we explore the problem of providing input privacy in PPFL systems for the horizontally-partitioned setting.
Models, training, and aggregation
To explore techniques for input privacy in PPFL, we first must be more precise about the training process.
In horizontally-partitioned federated learning, a common approach is to ask each participant to construct a model update by starting from a common global model and training locally using their own data. Since the data is horizontally partitioned, all participants have identically formatted data, and can train models that similarly have identical formats.
Different model formats are possible depending on the machine learning techniques used. Perhaps the most common format in horizontally-partitioned federated learning is a neural network, in which the participants agree on an architecture of connected layers before training begins, and the training process modifies weights (or parameters) within the layers to produce correct answers. Models and model updates can be represented by the values of these weights, usually arranged in a vector or matrix.
To combine individual model updates, the aggregator can simply average the weights associated with the participants' model updates to obtain an improved global model. This algorithm is called Federated Averaging (FedAvg), and it can be repeated many times to train a highly accurate global model.
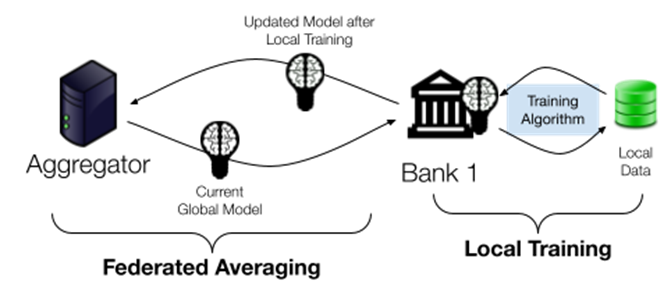
Figure 1: the FedAvg algorithm. The aggregator distributes the current global model to clients. The clients perform several iterations of training, each on their own local data. Then, the aggregator averages the resulting model updates to form the next version of the global model.
Input Privacy via Secure Aggregation
The FedAvg algorithm described in the last section does not provide input privacy---the aggregator receives individual model updates after each training phase, and could conduct one of the attacks described in our previous post to violate the privacy of participants.
One way of adding input privacy to this process is to use a secure aggregation protocol, which reveals the average of the model updates to the aggregator but protects the individual updates. Hiding individual updates from the aggregator is an effective defence against the "Attacks on Model Updates" described in our previous post.
Secure aggregation is an active area of research, and many algorithms have been proposed. A simple example is based on the cryptographic idea of secret sharing, which allows a secret value to be "split" into multiple shares. Each individual share reveals nothing about the original secret; the original secret can be recovered only by combining all of the shares. Furthermore, many secret sharing schemes are additively homomorphic, which means that addition can be performed on shares without combining them.
To use secret sharing for secure aggregation, each participant sends one share of their model update to each participant (keeping one for themselves). Then, each participant sums the shares they have received (plus the one held for themselves) and sends the result to the aggregator. By the additive homomorphism of the secret sharing scheme, the aggregator can combine the received shares to arrive at the sum of the original model updates---but has no way to access the individual updates!

Figure 2: secure aggregation by secret sharing. Each participant splits their local model into secret shares, then the participants sum up the shares and reconstruct the new global model. The protocol provides input privacy for each local model and reveals only the new global model.
This approach requires participants to send messages directly to each other and increases the amount of data each participant must send and receive. Recent research in this area has resulted in more efficient approaches, including systems that have been deployed at Google.
In the US-UK PETs Prize Challenges, the Scarlet Pets and Visa Research teams incorporated secure aggregation techniques as part of their winning solutions.
Input Privacy via Homomorphic Encryption
An alternative approach for adding input privacy to horizontally-partitioned federated learning is the use of homomorphic encryption instead of secure aggregation. In general, homomorphic encryption techniques allow computing on encrypted data without having to decrypt it first. Using homomorphic encryption, participants can encrypt their model updates using a common public encryption key and send the encrypted updates to the aggregator. If the aggregator does not have access to the corresponding secret key, then they cannot access individual updates.
To aggregate the model updates, the aggregator can use the addition operation of the homomorphic encryption scheme to add the encrypted updates together---resulting in a single encrypted aggregated model. Next, the aggregator needs to decrypt the aggregated model---but we already decided the aggregator must not have access to the secret key needed for decryption! The easiest way to solve this disconnect is to introduce another participant who is responsible for holding the secret key and decrypting only aggregated models. This participant must refuse to decrypt individual updates and must not collude with the aggregator.
Homomorphic encryption can be more efficient than secure aggregation in some cases, but the requirement of an additional participant who is guaranteed not to collude with the aggregator makes it difficult to deploy in many scenarios. Alternative approaches like threshold homomorphic encryption can eliminate the need for an additional participant, e.g. by secret sharing the secret key among participants. In the US-UK PETs Prize Challenges, techniques in this category were used by the PPMLHuskies, ILLIDANLAB, and MusCAT teams in their winning solutions.
Input Privacy via Secure Enclaves
Secure enclaves (also called Trusted Execution Environments or TEEs) provide a non-cryptographic approach to input privacy that instead relies on special security features of computer hardware. For example, Intel’s Software Guard Extensions (SGX), built into many Intel CPUs, allows programs within an enclave to compute on encrypted data without revealing that data to the CPU’s owner. Incorporating a secure enclave into a PPFL system enables untrusted parties to perform trusted computations, which can simplify the design of the system. Enclave-based approaches can also improve performance by avoiding the need for expensive cryptography.
Unlike cryptographic approaches, however, the security of an enclave depends on the trustworthiness and correctness of the CPU itself---so PPFL systems that rely on secure enclaves require trusting the manufacturer of the CPU.
Coming up Next
The input privacy techniques described in this post are easiest to apply when data is horizontally partitioned, because model aggregation can be performed by simple addition. When data is vertically partitioned, however, aggregation is much more complex, and different techniques are needed to provide input privacy. The next post in this series will describe this challenge and explore some common techniques for addressing it.
Recent Comments