This post is part of a series on privacy-preserving federated learning. The series is a collaboration between CDEI and the US National Institute of Standards and Technology (NIST). Learn more and read all the posts published to date on the CDEI blog or at NIST’s Privacy Engineering Collaboration Space.
Our first post in the series introduced the concept of federated learning—an approach for training AI models on distributed data by sharing model updates instead of training data. At first glance, federated learning seems to be a perfect fit for privacy, since it completely avoids sharing data.
However, recent work on privacy attacks has shown that it’s possible to extract a surprising amount of information about the training data, even when federated learning is used. These techniques fall into two major categories: attacks that target the model updates shared during training, and attacks that extract data from the AI model after training has finished.
This post summarises known attacks and provides recent examples from the research literature. The primary goal of the US-UK PETs prize challenges was to develop practical defences that augment federated learning frameworks to prevent these attacks; future posts in the series will describe these defences in detail.
Attacks on Model Updates
In federated learning, each participant submits model updates instead of raw training data during the training process. In our example from the last post - in which a consortium of banks wants to train an AI model to detect fraudulent transactions - the model updates may consist of updates to the model’s parameters (the components of the model that control how its predictions are made) rather than raw data about financial transactions. At first glance, the model updates may appear to convey no information about financial transactions.

Figure 1: Data extracted from model updates by the attack developed by Hitaj et al. [1]. The top row contains original training data; the bottom row contains data extracted from model updates.
However, recent research has demonstrated that it’s often possible to extract raw training data from model updates. One early example came from the work of Hitaj et al., who showed that it was possible to train a second AI model to reconstruct training data based on model updates. One example of their results appears in Figure 1: the top row contains training data used to train a model that recognises handwritten digits, and the bottom row contains data extracted from model updates by their attack.

Figure 2: Data extracted from model updates by the attack developed by Zhu et al. [2]. Each row corresponds to a different training dataset and AI model. Each column shows data extracted from model updates during training; columns with higher values for “Iters” represent data extracted later in the training process.
Later work by Zhu et al. suggests that this kind of attack is possible for many different kinds of models and their corresponding model updates. Figure 2 contains examples from four different AI models, showing that the attack is able to extract nearly-perfect approximations of the original training data from the model updates.
How to fix it
Attacks on model updates suggest that federated learning alone is not a complete solution for protecting privacy during the training process. Many defenses against such attacks focus on protecting the model updates during training, so that the organisation that aggregates the model updates does not have access to individual updates.
Privacy-enhancing technologies that protect the model updates during training are often said to provide input privacy - they prevent the adversary from learning anything about the inputs (i.e. the model updates) to the system. Many approaches for input privacy, including approaches used in the US-UK PETs prize challenges, rely on creative applications of cryptography. We’ll highlight several of these solutions throughout this blog series.
Attacks on Trained Models
The second major class of attacks target the trained AI model after training has finished. The model is the output of the training process, and often consists of model parameters that control the model’s predictions. This class of attacks attempts to reconstruct the training data from the model’s parameters, without any of the additional information available during the training process. This may sound like a more difficult challenge, but recent research has demonstrated that such attacks are feasible.

Figure 3: Training data extracted from a trained AI model using the attack developed by Haim et al. [3]. The top portion of the figure (a) shows extracted data; the bottom portion (b) shows corresponding images from the original training data.
AI models based on deep learning are particularly susceptible to the extraction of training data from trained models, because deep neural networks seem to memorise their training data in many cases. Researchers are still unsure about why this memorisation happens, or whether it is strictly necessary to train effective AI models. From a privacy perspective, however, this kind of memorisation is a significant problem. Recent work by Haim et al. demonstrated the feasibility of extracting training data from an AI model trained to recognise objects in images; an example appears in Figure 3.

Figure 4: Training data extracted from a diffusion model using the attack developed by Carlini et al. [4]. Diffusion models are designed for generating images; one popular example is OpenAI’s DALL-E.
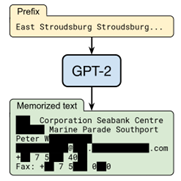
Figure 5: Training data extracted from a large language model (LLM) using the attack developed by Carlini et al. [5]. This example is from GPT-2, the predecessor of ChatGPT.
The challenge of memorised training data seems to be even worse for larger, more complex models - including popular large language models (LLMs) like ChatGPT and image generation models like DALL-E. Figure 4 shows an example of extracting training data from an image generation model using an attack developed by Carlini et al.; Figure 5 shows an example of extracting training data from a large language model using an attack by Carlini et al.
How to fix it
Attacks on trained models show that trained models are vulnerable, even when the training process is completely protected. Defences against such attacks focus on controlling the information content of the trained model itself, to prevent it from revealing too much about the training data.
Privacy-enhancing technologies that protect the trained model are often said to provide output privacy - they prevent the adversary from learning anything about the training data from the system’s outputs (i.e. the trained model). The most comprehensive approach for ensuring output privacy is called differential privacy, and is the subject of a previous NIST blog series and new draft guidelines. Many of the solutions developed in the US-UK PETs prize challenges leverage differential privacy to defend against attacks on the trained model; we’ll highlight several of these solutions throughout this blog series.
As always, we hope to hear from you with any questions and feedback. Please contact us at pets@cdei.gov.uk or privacyeng@nist.gov.
Coming Up Next
In our next post, we’ll introduce one of the key issues for federated learning: distribution of the data among the participating entities.
Recent Comments