Privacy Enhancing Technologies (PETs) could enable organisations to collaboratively use sensitive data in a privacy-preserving manner and, in doing so, create new opportunities to harness the power of data for research and development of trustworthy innovation. However, research DSIT commissioned with the Royal Society, and interviews we conducted throughout 2023, suggests organisations often struggle to articulate and the benefits (and costs) associated with using PETs. This can make it difficult to develop business cases for the adoption of PETs.
As part of the government’s work to address this, in June 2023, DSIT and the Information Commissioner’s Office (ICO) announced a collaboration to develop a tool to support organisations to assess costs and benefits of adopting PETs. This blog is a first step towards developing this tool and explores some examples of the costs and benefits associated with applying PETs to enable privacy-preserving federated learning.
What is privacy-preserving federated learning?
Federated learning is an approach to machine learning that involves training a model without the centralised collection of training data. In federated learning, a central server sends a copy of a partially trained model to each participant and collects model updates instead of data. Each participant constructs its model update by training the model locally on its own data - which it never shares. The resulting model updates can be aggregated and assembled to construct an improved global model.
Additional PETs can be ‘layered’ on top of federated learning to guard against reconstruction of sensitive data from model updates or outputs – this is privacy-preserving federated learning (PPFL). This type of scenario was the focus of the UK-US PETs Prize Challenges which concluded last year, and we are exploring the lessons from this in ongoing blog series with the US National Institute of Standards and Technology (NIST).
Costs and benefits
This blog considers a number of costs and benefits associated with deploying a PPFL system. Our baseline for comparison is a more traditional method of training an equivalent model on the same data collated into a central location. In this baseline we assume training data has been collected, is distributed across different entities, and contains personal or otherwise sensitive information. This baseline scenario therefore has costs associated with gathering this data into a central location. Baseline and federated scenarios are shown in Figure 1.
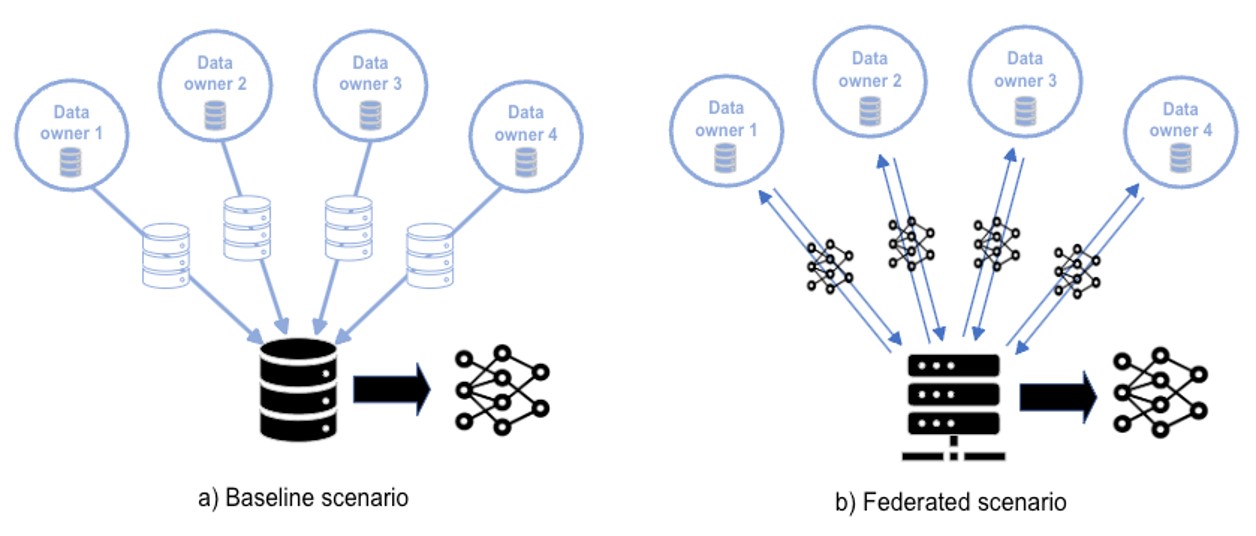
Figure 1: Comparison of a) the baseline scenario, where data is collected centrally; and b) the federated scenario where only model updates are shared.
Clearly the costs and benefits of adopting PPFL will be highly dependent on the specific context. Therefore, this blog will explore the different types of costs and benefits those looking to deploy PPFL should consider, rather than try to directly quantify these costs and benefits.
Infrastructure considerations
Both baseline and federated scenarios generally require developers to stand up a central server to orchestrate the learning process (though there are emerging techniques for fully decentralised federated learning without a central server). However, PPFL removes the need to transfer a copy of all the training data to a central database. This can lead to lower infrastructure and network overheads, compared to the baseline, especially for large training datasets.
On the other hand, bespoke privacy infrastructure can introduce additional costs. Depending on the privacy requirements of parties involved, it may be necessary to implement PPFL using secure CPU or GPU enclaves to provide input privacy. This will require purchasing hardware with enclave support or utilising a managed cloud service like Azure Confidential Computing or AWS Nitro Enclaves. Alternatively, homomorphic encryption or secure multi-party computation could be used to provide input privacy. Whilst these do not require access to bespoke hardware, they do introduce compute and network overheads. The scale of these overheads is highly dependent on the specific scheme used, e.g. compute overheads for homomorphic encryption-based approaches may be especially significant.
Both scenarios also involve costs associated with maintaining infrastructure. Firstly, there are costs associated with maintaining the central orchestration server. The baseline case requires the maintenance of a (potentially large) central database, and the implementation of appropriate data governance and security mechanisms to protect and secure any sensitive data. For PPFL, these costs and risks are devolved. For example, in federated learning scenarios where multiple organisations are collaborating, different data owners will bear these costs.
Secondly, there are costs associated with iterating models as new data arrives. In the baseline case, it is necessary to first ingest any new data into the central database before retraining the model. This step is not required for PPFL, which may mean that costs around this will be lower than the costs of updating models in a centralised system.
Organisations will need to trade off additional costs from duplication, versus savings from reduced risk/threat levels, and the ability to rely on each organisation’s existing governance approaches for their own data. In many cases, PPFL may be able to provide a saving here.
Technical maturity
Implementing PPFL requires many of the same technical activities as the baseline scenario, including designing system architecture, building a data pipeline and model development.
However, many of the relevant frameworks for PPFL are not as mature as frameworks such as TensorFlow, JAX and PyTorch used in traditional machine learning workflows. PPFL is therefore likely more complex to implement at present. This is likely to change as open-source federated learning frameworks, such as PySyft and Flower, continue to mature.
Since many PPFL tools and techniques are relatively new and not yet widely adopted, there are fewer people with the skills and experience required to design and deploy them, as well as a greater degree of expertise needed to work with less mature frameworks. This is likely to increase short term staffing costs and risks for PPFL approaches.
Legal considerations
As with any data project, organisations designing systems that use PPFL need to consult legal and regulatory teams to ensure – as a minimum - compliance with data protection and sector-specific regulations. Relevant frameworks will depend on the nature of the data as well as jurisdictions in scope (e.g. UK GDPR).
While legal consultation is a necessary cost, in principle, PPFL - rather than a centralised approach - can significantly reduce data protection risks. It reduces the amount of data that needs to be shared which helps to mitigate the risks associated with transferring and centrally storing data.
In the long term, this may simplify regulatory considerations and reduce associated legal costs. For example, ICO guidance states that when used appropriately, differentially private data can be considered anonymised. This anonymisation of outputs limits data protection risks caused by inappropriate or insecure disclosure or publication of personal data. Processing data locally also aligns with the legal requirement of data minimisation and data protection-by-design and default. This helps organisations to comply with the UK GDPR, can reduce the risk of data breaches and associated costs, and simplify contractual requirements.
Long-term benefits
Some of the additional early costs of deploying PPFL need to be weighed against longer term benefits.
Compared to a centralised approach, PPFL can improve long-term efficiency as it establishes a method and structure for integrating insights from different data providers into model training. In the long term, this could make it easier to add in new data sources. PPFL also embeds a more efficient way of iterating feedback to a central model into the system’s design. A PPFL approach allows a global model to continuously learn from data from different devices and organisations.
PPFL also allows organisations to use and monetise data assets that would not have previously been accessible. In removing the need for access to the full data, it protects the value of the data to the data owner. Through this, PPFL could firstly help organisations make their own data assets available to other organisations, and secondly, allow organisations to access other data assets which have become available in the same way. Making data that would not have previously been accessible due to the ‘copy problem’ (where data owners may be reluctant to share data due to the reduction in the data’s value that could follow) accessible, could create opportunities to benefit from the value of data e.g. by monetising access to it. In the long term, this could increase opportunities for working with data that organisations might have been hesitant to share.
Investing in PPFL may seem risky from a legal and compliance perspective. In contrast to centralised approaches, it is a relatively novel architectural approach that requires upfront investment amidst uncertainty about wider innovation in data privacy and future compliance requirements across different jurisdictions. However, as above, potential benefits of embedding federated learning to protect data by design are broad, and in reducing the need to move large amounts of data to integrate updates into centralised models, PPFL may be a more robust, future-proof approach and minimise the potential legal and compliance risks that organisations expose themselves to. Users and regulators may look favourably on organisations that do privacy well, and reputational benefits may result from the use of federated learning, which can offer substantial improvements in data security and privacy.
Adopters of PPFL may see the benefits above compound over time due to network effects; the deployment of more successful PPFL systems will encourage greater uptake, and as more organisations adopt PPFL, this will increase opportunities for use of PPFL across organisations and sectors, which will result in further opportunities for collaboration and to unlock greater value from data.
Summing up
PPFL, and PETs more generally, have the potential to enable organisations to make the most of the increasing opportunities for data collaboration and innovation. PPFL is an architectural approach that requires investment and thought early on, but once operational, by reducing the amount of data that needs to be stored centrally or shared, leads to efficiencies and greater security. PPFL provides opportunities for organisations to increase innovation and collaboration with data in ways that are not currently realised. We believe that this is in part due to a lack of understanding about costs and benefits of PPFL, and hope that enabling understanding of these costs and benefits will encourage further adoption of PETs.
DSIT and the ICO are continuing to work together to support organisations to assess the costs and benefits associated adopting PPFL, and other PETs. We will build on this work over the coming months and share further resources to help organisations to better understand how adopting PETs would impact them.
You can read more about PPFL in our ongoing blog series, and in the resources linked below:
- ICO: What is federated learning and what does it do?
- GitHub: What are PETs?
- ICO guidance on PETs
- ICO guidance on Federated Learning
- PETs Prize Challenge website
Get in touch at pets@dsit.gov.uk or PETs@ICO.org.uk
Recent Comments